
Wie bereits im Artikel Version 5.8 Teil 1 RecID unlimited angekündigt, stellt dieser Artikel Lösungsansätze für die Anpassung von Datensatz-IDs vor, wenn diese als Referenz auf einen Zieldatensatz gespeichert werden.
Hintergrund
Mit der Version 5.8 wurden die 64-Bit Datensatz-IDs eingeführt. Dadurch unterscheiden sich die IDs von Datensätzen zwischen der Version 5.7 und 5.8. Der vorliegende Artikel beschreibt, was beim Umstieg auf die Version 5.8 zu berücksichtigen ist, wenn eine Anwendung Datensatz-IDs persistent speichert um damit Daten zu referenzieren.
Beispiel
Mit der Version 5.7 wird eine Tabelle erstellt und anschließend ein Datensatz eingefügt. Anschließend wird der Datensatz gelesen und die Datensatz-ID (dezimal und hexadezimal) im Debugger ausgegeben:
@A+
@C+
main
{
RecRead(100,1,0);
DbgTrace('Version: ' + CnvAI(DbaInfo(_DbaClnRelMaj)) + '.' +
CnvAI(DbaInfo(_DbaClnRelMin)) +
' - Datensatz-ID: ' + CnvAI(RecInfo(100,_RecID)) +
' / 0x' + CnvAI(RecInfo(100,_RecID),_FmtNumHex | _FmtNumLeadZero,0,8));
}Die folgende Zeile präsentiert das Ergebnis:
Version: 5.7 - Datensatz-ID: 16.777.216 / 0x01000000Bei Ausführung mit der Version 5.8 ergibt sich das folgende Resultat:
Version: 5.8 - Datensatz-ID: 1 / 0x00000001Die ermittelte Datensatz-ID unterscheidet sich also zwischen den Versionen. Da die Datensatz-ID in den meisten Fällen nur temporär verwendet wird, stellt das auch kein Problem dar. Anders verhält es sich jedoch, wenn die Datensatz-ID z.B. als Feld im Datensatz gespeichert wird, um damit einen bestimmten Datensatz einer anderen Tabelle zu referenzieren (Abb.1).
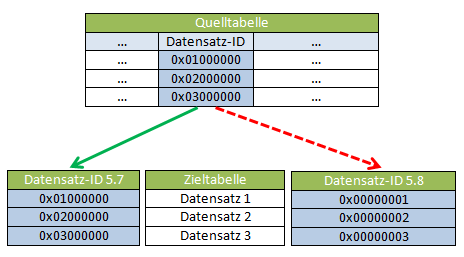 Abb.1: Referenzierung eines Datensatzes über seine Datensatz-ID
Abb.1: Referenzierung eines Datensatzes über seine Datensatz-IDIm Beispiel ist die Datensatz-ID als Feld in der Quelltabelle enthalten. Ein RecRead() über die gespeicherte Datensatz-ID in der Quelltabelle (z.B. RecID1) zur Ermittlung des Datensatzes in der Zieltabelle würde mit Version 5.8 ins Leere laufen, da jetzt seine Datensatz-ID eine andere ist (roter gestrichelter Pfeil).
Lösungsansatz
Der Ansatz besteht darin, aus der Datensatz-ID (Version 5.7) eine Datensatz-ID (Version 5.8) zu berechnen. Somit würde aus dem Wert 0x01000000 wieder 0x00000001, aus 0x02000000 wieder 0x00000002 usw. Die Referenz wäre auf diese Weise wiederhergestellt. Eine Funktion zum Berechnen der Datensatz-ID aus einem int-Wert zeigt der folgende Code:
// Konvertiert eine RecID, die in einem int-Wert abgelegt ist
sub ConvertSingleRecIDInt
(
aRecID : int; // Datensatz-ID (Version 5.7)
aTarTblIsSequential : logic; // Zieldatei (auf die die RecIDs verweisen)
// hat "sequentielles Einfügen" aktiviert?
)
: int; // Datensatz-ID (Version 5.8)
{
if (aTarTblIsSequential)
{
if (aRecID & 0x80 != 0)
ErrSet(_ErrValueOverflow);
else
return (
(aRecID & 0xFF000000) >> 24 & 0xFF |
(aRecID & 0x00FF0000) >> 8 |
(aRecID & 0x0000FF00) << 8 |
(aRecID & 0x000000FF) << 24
);
}
else
{
if (aRecID > 0)
ErrSet(_ErrValueOverflow);
else
return -aRecID;
}
}Die Funktion wandelt eine Datensatz-ID Version 5.7 (1. Argument) in eine Datensatz-ID Version 5.8 um (Rückgabewert). Je nachdem, ob die Option „Sequentielles Einfügen“ bei der Zieltabelle gesetzt ist oder nicht, vergibt der Datenbank-Server die Datensatz-IDs in einer anderen Reihenfolge. Die Berechnung unterscheidet sich dann ebenfalls. Ist „Sequentielles Einfügen“ bei der Tabelle gesetzt, wird der Funktion im zweiten Argument true übergeben, sonst false. Die Funktion setzt den globalen Fehlercode _ErrValueOverflow, wenn die resultierende Datensatz-ID >= 0x80000000 ist, da diese nicht im Wertebereich von int abgebildet werden können. Die Funktion sollte also nur verwendet werden, wenn der Prime-Counter der Zieldatei < 0x80000000 ist. Ist er größer, dann sollte die folgende Funktion verwendet werden:
// Konvertiert eine RecID, die in einem bigint-Wert abgelegt ist
sub ConvertSingleRecIDBigInt
(
aRecID : bigint; // Datensatz-ID (Version 5.7)
aTarTblIsSequential : logic; // Zieldatei (auf die die RecIDs verweisen)
// hat "sequentielles Einfügen" aktiviert?
)
: bigint; // Datensatz-ID (Version 5.8)
{
if (aTarTblIsSequential)
{
return (
(aRecID & 0x00000000FF000000\b) >> 24\b |
(aRecID & 0x0000000000FF0000\b) >> 8\b |
(aRecID & 0x000000000000FF00\b) << 8\b |
(aRecID & 0x00000000000000FF\b) << 24\b)
;
}
else
{
if (aRecID < 0\b)
return -aRecID;
return (0x100000000\b - aRecID);
}
}Da der Rückgabewert der Funktion bigint ist, sind alle umzurechnenden Datensatz-IDs darstellbar. Dies bedeutet jedoch auch, dass für die Speicherung der Datensatz-ID nun ein bigint-Feld vorgesehen werden muss.
Die Funktion ConvertRecID58
Sofern die Datensatz-ID in einem Datenbankfeld gespeichert ist, reicht die Berechnung der Datensatz-ID alleine nicht aus. Die ursprüngliche Datensatz-ID muss auch durch den neuen Wert ersetzt werden:
- On-demand
Die Datensatz-ID wird ersetzt, wenn diese das erste Mal benötigt wird. Dies hat zum Vorteil, dass nicht alle gespeicherten Datensatz-IDs ersetzt werden müssen, sondern nur jene, die auch tatsächlich referenziert werden. Nachteil ist, dass alle Stellen im Quelltext angepasst werden müssen, wo auf die ursprüngliche Datensatz-ID zugegriffen wird. Des Weiteren wäre ein zusätzliches Flag im Datensatz notwendig, damit hervorgeht, ob die Datensatz-ID bereits umgerechnet wurde oder nicht. - Alle Datensätze
Die Datensatz-IDs aller Datensätze wird berechnet und im Datensatz geändert. Der Vorteil hierbei ist, dass bei Verwendung desselben Datenbankfeldes für die neue Datensatz-ID keine Änderungen am Quelltext notwendig sind. Jedoch muss ein separater Durchlauf erfolgen, der einmalig alle Datensätze liest, die neue Datensatz-ID im Datenbankfeld einträgt und anschließend den Datensatz in der Datenbank aktualisiert.
Für die praktische Umsetzung der zweiten Methode kann die Funktion ConvertRecID58 verwendet werden:
sub ConvertRecID58
(
aTblNo : int; // Tabellennummer in der die RecIDs stehen
aSbrNoSrc : int; // Teildatensatznummer in aTblNo (Konvertierungsquelle)
aFldNoSrc : int; // Feldnummer in aSbrNo (Konvertierungsquelle)
aTarTblIsSequential : logic; // Zieldatei (auf die die RecIDs verweisen) hat "sequentielles Einfügen" aktiviert?
opt aSbrNoTar : int; // Teildatensatznummer in aTblNo (Konvertierungsziel). Wenn nicht angegeben, wird aSbrNoSrc verwendet.
opt aFldNoTar : int; // Feldnummer in aTblNo (Konvertierungsziel). Wenn nicht angegeben, wird aSbrNoSrc verwendet.
)
Die Funktion liest nacheinander alle Datensätze der Datei aTblNo und aktualisiert die Datenätze mit der neu berechneten Datensatz-ID. Das Feld, welches die Datensatz-ID (Version 5.7) speichert, wird über die Argumente aTblNo, aSbrNoSrc (Teildatensatznr.) und aFldNoSrc (Feldnr.) angegeben. Es muss den Datentyp int oder bigint besitzen. Wird nichts weiter angegeben, dann wird die Datensatz-ID im selben Feld gespeichert. Soll die Original-Datensatz-ID erhalten bleiben, kann über aSbrNoTar und aFldNoTar ein abweichendes Datenbankfeld im selben Datensatz angegeben werden.
Beispiel-Datenbank
Anhand der Beispiel-Datenbank am Ende des Blog-Artikels haben Sie die Möglichkeit, die beschriebene Funktion zu testen. Die Datenbank enthält berühmte Filmpaare. Eine Anleitung zur Verwendung des Beispiels befindet sich im Dokument ReadMe.rtf, das ebenfalls im Archiv enthalten ist.