
Mit der Verwendung von Filtern ist die Möglichkeit gegeben, die Datenmenge einzuschränken. Allerdings ist es manchmal notwendig die genaue Anzahl der Datensätze zu ermitteln, die dem Kriterium des Filters entsprechen. Dies ist, anders als bei Selektionen, nicht über RecInfo() zu erreichen. Es gibt natürlich die Option die Anzahl zu ermitteln, indem alle Datensätze unter Verwendung des Filter-Deskriptors erneut gelesen werden. Dies dauert allerdings sehr lange (in Abhängigkeit von der Anzahl der zu lesenden Datensätze) und ist daher nicht empfehlenswert. Heute möchte ich Ihnen einen Weg aufzeigen, wie dies deutlich schneller realisiert werden kann.
Datei anlegen
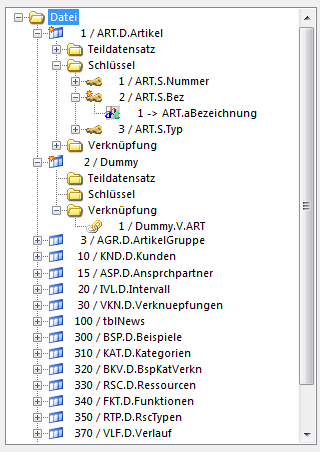
Als erstes ist es notwendig eine Hilfsdatei (vgl. Screenshot: Datei Dummy) anzulegen. In dieser Datei wird nur eine Verknüpfung eingefügt. Diese Datei benötigt allerdings keinen Schlüssel und auch keinen Teildatensatz.
Verknüpfung erzeugen
Als nächstes wird nun eine Verknüpfung in der Dummy-Datei angelegt. Hier wird nun als Zieldatei die Datei angegeben, welche die zu filternden Daten enthält. Als Schlüssel kann ein bereits vorhandener gewählt werden. Hier ist darauf zu achten, dass dieser Schlüssel alle für den Filter relevanten Felder beinhaltet. Diese Verknüpfung liefert nun alle in der Datei befindlichen Datensätze.
Nun kann ein Filter definiert werden, welcher die gewünschten Kriterien enthält. Ist dies geschehen, hat man nun die Möglichkeit über RecLinkInfo() mit dem Informationstyp _RecCount und der Angabe des Filter-Deskriptors die Anzahl der Datensätze zu ermitteln, welche das Filterkriterium erfüllen.
{
...
tFilter # RecFilterCreate(1, 2);
// Es sollen alle Feldinhalte ermittelt werden, die Visual im Namen
// haben
tFilter->RecFilterAdd(1, _FltAND, _FltLikeCI, '*Visual*');
$RecList->wpDbFilter # tFilter;
tAnzahl # RecLinkInfo(1, 2, 1, _RecCount, tFilter);
...
}
6 Kommentare
Aha, also RecInfo fragt nur einen schon vorhandenen Wert ab und ist dadurch natürlich sehr schnell, danke für die Klarstellung.
Man könnte das hier vorgestellte Verfahren aber sicherlich trotzdem auf die eine oder andere Weise vereinfachen:
a) So wäre es z.B. praktisch, wenn man die temporäre Tabelle mit der temporären Verknüpfung auf die zu zählenden Daten ggf. ad hoc im Code erstellen könnte.
b) Eine weitere Möglichkeit wäre sicherlich, den Befehlssatz für Filter einfach entsprechend zu erweitern.
@Th.Eichele
Das Laufzeitverhalten wird durch die aktuelle Cachebelegung und die I/O-Leistung des Datenbankservers bestimmt. Liegen die Schlüsselwerte nicht im Cache, kann es auch etwas dauern – es ist aber in jedem Fall um ein mehrfaches schneller, als die Anzahl durch das Lesen der Datensätze zu ermitteln.
Bei RecLinkInfo() muss die Anzahl der Sätze immer über die Schlüsselwerte neu ermittelt werden, ein Filter verändert die Dauer dieses Vorgangs nicht.
Bei RecInfo() wird dagegen nur ein Zähler (Tabelle oder Selektion) abgefragt, bei Angabe eines Filterdeskriptors müssten alle Schlüsselwerte der Tabelle durchlaufen werden, was eben auch länger dauern kann und bei der Verwendung von RecInfo() nicht direkt ersichtlich ist – das Laufzeitproblem tritt meist erst beim Kunden auf 🙁
Aus diesem Grund hat RecInfo() keine Filtermöglichkeit, mit dem oben beschriebenen Verfahren geht’s aber trotzdem.
Der Trick liegt möglicherweise darin, dass RecLinkInfo eine Verknüpfung UND einen Filterdeskriptor zu verarbeiten versteht, wohingegen RecInfo nichts mit dem Filterdeskriptor anzufangen weiss (jedenfalls steht nichts davon in der Hilfe).
RecLinkInfo weiss gerade dank des Filters, welche Sätze er zu berücksichtigen hat. Die gute Performance resultiert daraus, dass (wie auch bei RecInfo) nur der angegebenen Schlüssel überprüft werden muss.
Würde man RecInfo um die Möglichkeit der Angabe eines Filterdeskriptors erweitern, müsste sich Fabians Verbesserungsvorschlag eigentlich umsetzen lassen oder?
Der Trick ist zwar genial, aber vielleicht etwas entwicklerfremd.
Wenn es mit dem RecLinkInfo-Befehl schneller geht, als alle Datensätze einzeln zu zählen, warum kann dann das Filter-Handle nicht auch beim Befehl RecCount() angeben werden? Das müsste ja schlussendlich denselben Effekt haben. Eine leere Verknüpfung auf einen Schlüssel kann doch nicht wirklich einen Performancevorteil gegenüber dem Schlüssel selbst generieren, oder sehe ich da etwas falsch?
Interessanter Trick
und die Laufzeit ist hier vernachlässigbar ?