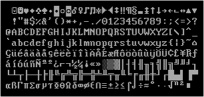
Für die Speicherung und Verarbeitung von Zeichenketten und Texten ist die Basis ein Zeichensatz. CONZEPT 16 verwendet aktuell einen Zeichensatz, dessen Besonderheiten durch eine lange Historie entstanden sind.
Die CONZEPT 16 Version 1.0 lief unter DOS auf dem WANG PC und verwendete daher den WSCII-Zeichensatz. Ab Version 1.2 gab es auch eine Version für den IBM-PC, auf dem dann der dort vorhandene "OEM"-Zeichensatz (IBM Codepage 437) genutzt wurde – mit einer Ausnahme: Um eine teilweise Kompatibilität mit den Datenbanken des WANG PCs zu erreichen, blieben die deutschen Umlaute an den Codepositionen des WSCII. Somit waren schon damals Zeichensatz-Umwandlungen notwendig.
Mit der ersten Windows-Version gab es wieder einen neuen Zeichensatz: Windows 1252 (Westeuropa) – gemeinhin ANSI-Zeichensatz genannt. Die ASCII-Zeichen 32 bis 126 sind mit dem OEM-Zeichensatz identisch. Um unter DOS erstellte Datenbanken ohne Datenkonvertierung weiterzuverwenden, wurden 51 OEM-Zeichen, die auch im Windows-Character-Set zu finden sind, an den alten Codepositionen belassen. Alle anderen Zeichen der Codepage 1252 sind ebenfalls bei CONZEPT 16 vorhanden, liegen jedoch teilweise auf anderen Positionen.
Bei jedem Datenaustausch mit dem Betriebssystem, anderen Programmen oder externen Daten muss daher eine Umwandlung der Zeichen in den Zielzeichensatz erfolgen.
Anwendungsbeispiele
Ausgabe per Fsi-Befehl
Sollen Daten mit den Fsi-Befehlen in eine externe Datei geschrieben oder aus einer externen Datei gelesen werden, spielt der verwendete Zeichensatz eine große Rolle. Bei den Befehlen FsiRead() und FsiWrite() ist zu beachten, dass eine automatische Zeichensatzwandlung zwischen dem OEM- und dem CONZEPT 16-Zeichensatz stattfindet. Wird als Option bei FsiOpen() entweder _FsiANSI oder _FsiPure angegeben, wird entweder in den ANSI-Zeichensatz oder gar nicht gewandelt.
Die Konvertierung in den Zielzeichensatz wird beim Schreiben von Dateien wie folgt durchgeführt:
// 1. Datei im ANSI-Format schreiben
tFsiHdl # FsiOpen('C:\Datei.txt', _FsiStdWrite | _FsiANSI);
tFsiHdl->FsiWrite('ÄäÖöÜüß');
// 2. Datei ohne automatische Konvertierung öffnen
tFsiHdl # FsiOpen('C:\Datei.txt', _FsiStdWrite | _FsiPure);
// Text im UTF-8-Zeichensatz hinzufügen
tFsiHdl->FsiWrite(StrCnv('ÄäÖöÜüß', _StrToUTF8));Mit der zweiten Möglichkeit kann der Dateiinhalt auch in andere Zeichensätze gewandelt werden.
Für die Konvertierung beim Auslesen müssen bei dem Befehl StrCnv() die Konstanten _StrFrom... verwendet werden.
Eigenschafts-Wert mit Unicode in Dialogobjekten setzen
Um in einem Dialog Unicode-Zeichenketten anzuzeigen muss der Dialog im Designer geöffnet werden und beim Öffnen ein Haken bei Unicode gesetzt werden. Anschließend können allen Eigenschaften, vor denen ein Stern im Eigenschaftsfenster steht Unicode-Zeichenketten zugewiesen werden. Soll dies prozedural geschehen, muss wie folgt vorgegangen werden:
$btnOk->wpCaption # StrCnv(StrCnv('Übernehmen', _StrToUTF8),
_StrFromANSI);Das StrCnv(..., _StrFromANSI) ist notwendig, damit der ANSI-Zeichensatz als Quellzeichensatz verwendet wird. Ansonsten sind die Sonderzeichen an anderen Codepositionen.
Alle anderen Eigenschaften können wie gewohnt ohne Konvertierung gesetzt werden. Es ist zu beachten, dass nicht allen Objekten Unicode-Zeichenketten zugewiesen werden können.
7 Kommentare
Danke für diese Informationen. Ich habe zu diesem Thema an anderer Stelle in diesem Blog schon Kommentare hinterlassen und habe die Art, in der man die StrCnv-Aufrufe durchführen musste ebenfalls nicht verstanden. Nun ist die Sachlage einigermassen klar.
Ein Unicode-String-Typ wäre natürlich begrüssenswert, daneben wäre evtl. auch eine "wpCaptionUnicode" bei deren Zusweisung keine automatische Konvertierung durchgeführt wird, eine Lösung.
@David
Bei der Zuweisung an "wpCaption" findet immer eine Wandlung von CONZEPT 16-Zeichensatz in den Windows-Zeichensatz statt (das ist für die Bildschirmanzeige notwendig) – dadurch wird ein UTF-8-String aber unbrauchbar.
Um diesen Effekt auszuschalten, verwenden wir die "Umkehroperation", also Windows nach C16 (_StrFromAnsi). Beide Operationen heben sich gegenseitig auf, und in der angezeigeten Caption steht der Unicode-String.
Ein eigener String-Typ für Unicode befindet sich schon in der Entwicklung.
Der Aufruf
StrCnv(StrCnv(‘Übernehmen’, _StrToUTF8), _StrFromANSI)
bereitet mir auch nach dieser Erklärung noch Kopfschmerzen und erscheint einfach falsch.
Brechen wir das o.g. Statement mal in seine Einzelteile auf:
‘Übernehmen’ verwendet, wenn ich den Blogeintrag richtig verstehe, den C16-eigenen Zeichensatz.
StrCnv(‘Übernehmen’, _StrToUTF8) wandelt den Text ins UTF8-Format, so steht es zumindest in der Hilfe.
Nun liegt der Text also augenscheinlich im UTF8-Format vor und dann kommt plötzlich ein Aufruf von StrCnv, in dem man unlogischerweise angibt, der Text läge im ANSI-Format vor.
Das will mir nicht einleuchten und ich habe Angst davor, dass es mir irgendwann sinnvoll erscheint. Ich bin mal so überheblich zu behaupten, dass mich der Grund nicht interessieren sollte und eindeutig ein Implementationsdetail ist, das vor dem Entwickler verborgen sein sollte.
Ein eigener Typ für Unicode-Zeichenfolgen (ualpha?), das wäre ein Ansatz in die richtige Richtung.
Immer wenn UTF8 intern verwendet wird, muss es ins interne Zeichensatz gewandelt werden; ok
Begriffen. Danke!
@Carlo
Für die Verarbeitung von Zeichenketten verwendet CONZEPT 16 einen eigenen Zeichensatz.
Damit die Umlaute korrekt verarbeitet werden können, muss der String in den CONZEPT 16-Zeichensatz gewandelt werden. Mit der Option _StrFromANSI wird diese Wandlung vorgenommen.
jetzt wird einiges klar!
ich verstehe nur nicht, weshalb es nicht
StrCnv(StrCnv(‘äöü’, _StrFromANSI), _StrToUTF8);
heisst.
Also zuerst from ansi und dann to UTF8
oder würde beides funktionieren?
vielen Dank für die interessante Hintergrundinformation.