
Der CONZEPT 16-ODBC-Treiber wurde für die Version 5.6 komplett neu geschrieben. Neben der Unterstützung von 64-Bit-ODBC-Applikationen war dabei besonders das Thema Performance von hoher Bedeutung. In diesem Artikel möchte ich die Techniken vorstellen, die für eine höhere Geschwindigkeit sorgen.
Der größte Performancevorteil entsteht durch die Nutzung der Passdown-Technologie. Die SQL-Abfragekriterien werden dabei nicht mehr auf dem lokalen Rechner vom ODBC-Treiber verarbeitet, sondern direkt an den Datenbankserver „durchgereicht“. Der Datenbankserver prüft den angegebenen Filter und gibt nur die passenden Datensätze an den Treiber zurück. Im Folgenden soll gezeigt werden, wie bestimmte Abfragen auf eine Kundentabelle von der Verbesserung profitieren. Zu diesem Zweck wurden die Abfragen sowohl mit dem ODBC-Treiber der Version 5.5 (ohne Passdown) und dem neuem ODBC-Treiber der Version 5.6 (mit Passdown) durchgeführt und die Laufzeiten verglichen.
Abfragen einer Tabelle
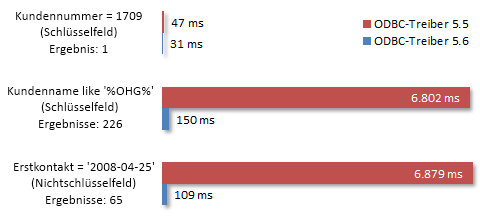 Abfrage von Tabelle „Kunden“ (48.311 Datensätze, 4 Spalten)
Abfrage von Tabelle „Kunden“ (48.311 Datensätze, 4 Spalten)Der erste Fall zeigt, dass Abfragen über Schlüsselfelder nur minimal von der neuen Technologie profitieren. Ein Direktzugriff per Kundennummer kann über den Schlüssel (Index) abgearbeitet werden und liefert in sehr kurzer Zeit den gewünschten Datensatz.
Anders verhält es sich bei Ähnlichkeitsabfragen: Das Feld Kundenname aus dem zweiten Fall ist zwar in einem Schlüssel enthalten, dennoch müssen alle Sätze auf das Kriterium geprüft werden – ein Direktzugriff ist nicht möglich. Diese Überprüfung kann durch die Verarbeitung auf dem Server sehr viel schneller durchgeführt werden, da nur die 226 Ergebnissätze an den Client übertragen werden müssen. Weiterer Pluspunkt: Da über das Feld Kundenname ein Schlüssel definiert ist, müssen die Sätze im Datenbankserver nicht entpackt werden. Das Kriterium kann also bereits anhand der Schlüsselwerte geprüft werden.
Die dritte Abfrage über das Feld „Erstkontakt“ macht deutlich, dass die Passdown-Technologie bei der Verwendung von Nichtschlüsselfeldern ihre volle Leistung zeigt, und zwar unabhängig vom verwendeten Vergleichsoperator.
Joins von mehreren Tabellen
Abfragen über mehrere Tabellen (Joins) werden ebenfalls durch die Passdown-Verarbeitung beschleunigt:
 Join von Tabelle „Kunden“ (92 Datensätze) mit Tabelle „Aufträge“ (89 Datensätze), Abfrage von 2 Spalten
Join von Tabelle „Kunden“ (92 Datensätze) mit Tabelle „Aufträge“ (89 Datensätze), Abfrage von 2 SpaltenBei Abfragen über mehrere Tabellen werden alle Join-Kriterien ebenfalls an den Datenbankserver geschickt und von diesem verarbeitet. Zusätzlich macht sich hier eine weitere Optimierung bemerkbar: Der Datenbankserver schickt nur die Feldwerte zurück, die im SQL-Query abgefragt werden.
Zuletzt sollen zwei Abfragen auf Tabellen mit vielen Datensätzen gezeigt werden.
 Join von Tabelle „Kunden“ (1.198.254 Datensätze) mit Tabelle „Aufträge“ (11.379.865 Datensätze), Abfrage von 2 Spalten
Join von Tabelle „Kunden“ (1.198.254 Datensätze) mit Tabelle „Aufträge“ (11.379.865 Datensätze), Abfrage von 2 SpaltenIm ersten Fall wurden alle Kunden eines bestimmten Postleitzahl-Bereichs herausgefiltert und anschließend alle zugehörigen Aufträge aufgelistet. Da für die Postleitzahl in der Tabelle „Kunden“ ein Schlüssel definiert ist, kann diese Abfrage in beiden Treibern sehr schnell verarbeitet werden.
Bei der zweiten Abfrage erfolgt die Einschränkung in der verknüpften Tabelle: Hier sollen nur die Aufträge eines bestimmten Tages zurückgeliefert werden. Da über das Auftragsdatum kein Schlüssel definiert ist, müssen pro Kunde alle Aufträge durchgelesen werden. Diese Abfrage ließe sich in der Praxis durch verschiedene Maßnahmen deutlich optimieren. Dennoch zeigt sie exemplarisch, dass auch bei ungünstigen SQL-Queries durch die Erweiterungen des ODBC-Treibers eine hohe Leistungssteigerung erreicht wird.
13 Kommentare
@Andreas
Bezüglich der Abstürze des Datenbank-Prozesses stellen sich für uns ein paar Fragen. Bitte nehmen Sie mit unserem Support Kontakt auf (Tel. 06104 660-300).
Gibt es zu dem Thema inzwischen Neuigkeiten? Wir hatten auch mehrere Serverabstürze und müssen seitdem den ‘alten’ ODBC-Treiber nutzen. Dessen ‘Performance’ ist aber – wie wir ja wissen – deutlich steigerbar…
Der Fall/die Daten lagen Ihnen bereits damals schon vor, aber wir gerade sie gerade nochmals neu dem Support gemeldet…
@Andros,
Bitte teilen Sie dem Support mit, bei welcher Abfrage es zu einem Rollback der Datenbank kommt.
Das Problem mit sich aufhängenden ODBC-Abfragen besteht immer noch! Es führt ja sogar zu einem ROLLBACK der Datenbank. Daß die direkte Lösung nicht bei Vectorsoft liegt, ist eine Sache – warum wird dann aber nicht wenigstens eine ätere "langsamere" dafür aber voll funktionsfähige Version der ODBC-Treiber in den Releases eingesetzt?? Sehr ärgerlich das beim Endkunden…. ;(
@Andros
Schicken Sie bitte die ODBC Statements, welche Probleme bereiten, zur Bearbeitung an den Support von vectorsoft.
Bei gewissen Abfragen hägt die neue ODBC aber irgendwie….leider… also im Moment nicht uneingeschränkt für den Echtbetrieb nutzbar!!
@Andros
Ja, das ist egal, der ODBC-Treiber kann sowohl als 32- als auch 64-Bit-Version mit jedem CONZEPT 16-Server (32- und 64-Bit) arbeiten.
Und dabei ist es egal, ob die Workstations gemischt 32 oder 64bit Betriebsysysteme fahren, wenn das Serversystem rein 64bit ist?
@Robert
vielen Dank für die prompte Lieferung der Vergleichswerte.
Es hat mich erstaunt, dass bei dem 3. Vergleich (Nichtschlüsselfeld) der ODBC-Treiber 5.6 sogar fast doppelt so schnell ist wie die Verwendung von _SelServer.
Ich finde diese Vergleichswerte machen noch deutlicher, welche Leistung hinter dem ODBC-Treiber der Version 5.6 steckt.
Besonders beim 3. Vergleich (Nichtschlüsselfeld) wird deutlich, dass mit der Passdown-Technologie ähnliche Resultate wie bei der Verwendung von _SelServer erreicht werden. Bei Schlüsselfeldern hingegen ist die Selektion in der Datenbank schneller, da bei ODBC mehr Overhead anfällt.
Die Zeiten der Joins lassen sich allerdings schlecht mit den Selektionen vergleichen. Joins haben eine neue temporäre Tabelle als Resultat, Selektionen beziehen sich hingegen auf eine vorhandene Datenbanktabelle.
@Klaus
Für die 3 Abfragen auf die Kundentabelle (Bild 1) habe ich ein paar Vergleichswerte mit dynamischen Selektionen ermittelt:
1) Kundennummer = 1709 (Schlüsselfeld)
ODBC-Treiber 5.5: 47 ms
ODBC-Treiber 5.6: 31 ms
SelRun (lokal): 9 ms
SelRun (_SelServer): 31 ms
2) Kundenname like ‘%OHG%’ (Schlüsselfeld)
ODBC-Treiber 5.5: 6.802 ms
ODBC-Treiber 5.6: 150 ms
SelRun (lokal): 78 ms
SelRun (_SelServer): 31 ms
3) Erstkontakt = ‘2008-04-25’ (Nichtschlüsselfeld)
ODBC-Treiber 5.5: 6.879 ms
ODBC-Treiber 5.6: 109 ms
SelRun (lokal): 6.088 ms
SelRun (_SelServer): 203 ms
Das sind sehr deutliche Verbesserungen, insbesondere dann, wenn es um Nicht-Schlüsselfelder geht.
Gibt es eigentlich auch Vergleichswerte, wie lange diese Abfragen mittels datenbankeigener Selektion brauchen ?