
As already announced in the article Version 5.8 Part 1 RecID unlimited, this article presents solution approaches for the adaptation of dataset IDs if they are saved as a reference to a target dataset.
Background
64-bit data set IDs were introduced with version 5.8. As a result, the IDs of data sets differ between versions 5.7 and 5.8. This article describes what needs to be taken into account when switching to version 5.8 if an application persistently saves data set IDs in order to reference data.
Beispiel
With version 5.7, a table is created and then a data record is inserted. The data record is then read and the data record ID (decimal and hexadecimal) is output in the debugger:
@A+
@C+
main
{
RecRead(100,1,0);
DbgTrace('Version: ' + CnvAI(DbaInfo(_DbaClnRelMaj)) + '.' +
CnvAI(DbaInfo(_DbaClnRelMin)) +
' - Datensatz-ID: ' + CnvAI(RecInfo(100,_RecID)) +
' / 0x' + CnvAI(RecInfo(100,_RecID),_FmtNumHex | _FmtNumLeadZero,0,8));
}The following line presents the result:
Version: 5.7 - Datensatz-ID: 16.777.216 / 0x01000000When executed with version 5.8, the following result is obtained:
Version: 5.8 - Datensatz-ID: 1 / 0x00000001The determined data record ID therefore differs between the versions. As the data record ID is only used temporarily in most cases, this is not a problem. However, the situation is different if the data record ID is saved as a field in the data record, for example, in order to reference a specific data record in another table (Fig. 1).
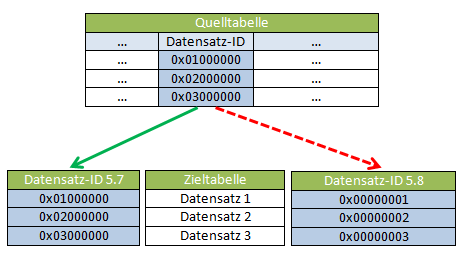 Abb.1: Referencing a data record via its data record ID
Abb.1: Referencing a data record via its data record IDIn the example, the data record ID is contained as a field in the source table. A RecRead() via the stored record ID in the source table (e.g. RecID1) to determine the record in the target table would come to nothing with version 5.8, as its record ID is now a different one (red dashed arrow).
Solution approach
The approach is to calculate a data record ID (version 5.8) from the data record ID (version 5.7). This would turn the value 0x01000000 back into 0x00000001, 0x02000000 back into 0x00000002 and so on. The reference would be restored in this way. The following code shows a function for calculating the data record ID from an int value:
// Converts a RecID that is stored in an int value
sub ConvertSingleRecIDInt
(
aRecID : int; // Data record ID (Version 5.7)
aTarTblIsSequential : logic; // Target file (to which the RecIDs refer)
// has “sequential insertion” activated?
)
: int; // Data record ID (Version 5.8)
{
if (aTarTblIsSequential)
{
if (aRecID & 0x80 != 0)
ErrSet(_ErrValueOverflow);
else
return (
(aRecID & 0xFF000000) >> 24 & 0xFF |
(aRecID & 0x00FF0000) >> 8 |
(aRecID & 0x0000FF00) << 8 |
(aRecID & 0x000000FF) << 24
);
}
else
{
if (aRecID > 0)
ErrSet(_ErrValueOverflow);
else
return -aRecID;
}
}The function converts a data record ID version 5.7 (1st argument) into a data record ID version 5.8 (return value). Depending on whether the “Sequential insert” option is set for the target table or not, the database server assigns the data record IDs in a different order. The calculation then also differs. If “Sequential insert” is set for the table, the function is passed true in the second argument, otherwise false. The function sets the global error code _ErrValueOverflow if the resulting record ID >= 0x80000000, as these cannot be mapped in the value range of int. The function should therefore only be used if the prime counter of the target file is < 0x80000000. If it is greater, the following function should be used:
// Converts a RecID that is stored in a bigint value
sub ConvertSingleRecIDBigInt
(
aRecID : bigint; // Data record ID (Version 5.7)
aTarTblIsSequential : logic; // Target file (to which the RecIDs refer)
// has “sequential insertion” activated?
)
: bigint; // Data record ID (Version 5.8)
{
if (aTarTblIsSequential)
{
return (
(aRecID & 0x00000000FF000000\b) >> 24\b |
(aRecID & 0x0000000000FF0000\b) >> 8\b |
(aRecID & 0x000000000000FF00\b) << 8\b |
(aRecID & 0x00000000000000FF\b) << 24\b)
;
}
else
{
if (aRecID < 0\b)
return -aRecID;
return (0x100000000\b - aRecID);
}
}As the return value of the function is bigint, all data set IDs to be converted can be displayed. However, this also means that a bigint field must now be provided to store the data record ID.
The ConvertRecID58 function
If the data record ID is stored in a database field, calculating the data record ID alone is not sufficient. The original record ID must also be replaced by the new value:
- On-demand
The data record ID is replaced when it is required for the first time. The advantage of this is that not all stored data set IDs need to be replaced, but only those that are actually referenced. The disadvantage is that all places in the source code where the original data set ID is accessed must be adapted. Furthermore, an additional flag would be required in the data record to indicate whether the data record ID has already been converted or not. - All data records
The data record IDs of all data records are calculated and changed in the data record. The advantage here is that no changes need to be made to the source code if the same database field is used for the new data record ID. However, a separate run must be carried out that reads all data records once, enters the new data record ID in the database field and then updates the data record in the database.
The ConvertRecID58 function can be used for the practical implementation of the second method:
sub ConvertRecID58
(
aTblNo : int; // Table number in which the RecIDs are located
aSbrNoSrc : int; // Partial data record number in aTblNo (conversion source)
aFldNoSrc : int; // Field number in aSbrNo (conversion source)
aTarTblIsSequential : logic; // Target file (to which the RecIDs refer) has “sequential insertion” activated?
opt aSbrNoTar : int; // Partial data record number in aTblNo (conversion target). If not specified, aSbrNoSrc is used.
opt aFldNoTar : int; // Field number in aTblNo (conversion target). If not specified, aSbrNoSrc is used.
)
The function reads all data records in the aTblNo file one after the other and updates the data records with the newly calculated data record ID. The field that stores the data record ID (version 5.7) is specified via the arguments aTblNo, aSbrNoSrc (partial data record no.) and aFldNoSrc (field no.). It must have the data type int or bigint. If nothing else is specified, the data record ID is saved in the same field. If the original data record ID is to be retained, a different database field can be specified in the same data record via aSbrNoTar and aFldNoTar.
Example database
You can use the sample database at the end of the blog article to test the function described. The database contains famous movie pairs. Instructions on how to use the example can be found in the ReadMe.rtf document, which is also included in the archive.